





- Tổng quan
Xử lý văn bản trong bài toán xử lý ngôn ngữ tự nhiên là một lĩnh vực nghiên cứu rộng, phức tạp và có nhiều ứng dụng trong thực tế. Một trong những ứng dụng phổ biến đó là bài toán phân loại văn bản. Phân loại văn bản là nhiệm vụ gán nhãn cho các tài liệu hoặc chủ đề hoặc câu dựa trên nội dung của chúng. Phân loại văn bản có thể dựa trên các thuật toán học máy hoặc các phương pháp thống kê.
Mô hình ngôn ngữ thống kê n-gram đóng vai trò quan trọng trong phân loại văn bản trong xử lý ngôn ngữ tự nhiên. Sử dụng mô hình n-gram để giải quyết bài toán này sẽ có nhiều lợi ích. Mô hình thống kê n-gram là một trong những phương pháp cơ bản và phổ biến trong xử lý ngôn ngữ tự nhiên để dự đoán xác suất xuất hiện của một từ dựa trên các từ liền kề trước đó.
Một n-gram là một chuỗi gồm n từ liên tiếp trong một câu hoặc đoạn văn. Giá trị của n chỉ ra số từ được xem xét trong một chuỗi, đó là:
- Unigram (n=1): chuỗi gồm 1 từ
- Bigram (n=2): chuỗi gồm 2 từ liên tiếp
- Trigram (n=3): chuỗi gồm 3 từ liên tiếp
- N-gram (n): chuỗi gồm n từ liên tiếp.
Mô hình n-gram dựa trên xác suất có điều kiện để dự đoán từ tiếp theo trong chuỗi dựa trên n-1 từ trước đó. Vì vậy để xây dựng mô hình n-gram, chúng ta thường phải thực hiện các bước sau:
- Thu thập dữ liệu: Sử dụng một tập dữ liệu lớn để thu thập tất cả các n-gram có thể có từ văn bản.
- Đếm tần suất: Đếm tần suất xuất hiện của mỗi n-gram
- Tính toán xác suất: Xác suất của n-gram được tính bằng tần suất xuất hiện của n-gram đó chia cho tổng số lần xuất hiện của n-1 từ trước đó.
Với cách thức xây dựng như vậy, mô hình ngôn ngữ thống kê n- gram có các ưu điểm sau:
- Đơn giản và dễ hiểu: dễ triển khai và không yêu cầu tính toán phức tạp.
- Nhanh và hiệu quả: Với các giá trị n nhỏ, mô hình n-gram có thể được tính toán nhanh chóng và hiệu quả.
- Phù hợp với các ứng dụng cục bộ: N-gram nắm bắt tốt các ngữ cảnh ngắn, dự đoán từ tiếp theo.
Đối với bài toán phân loại văn bản thì cách tiếp cận mô hình ngôn ngữ thống kê N-gram còn có thêm các lợi thế và ưu điểm khác.
Một là, không giống như tiếng Anh, nhận dạng từ trong tiếng Việt không tuân theo khoảng trắng, do đó, cách tiếp cận phân loại dựa trên túi từ đối với bài toán phân loại văn bản tiếng Việt gặp phải khó khăn đó là vấn đề phân đoạn từ. Hiệu quả của việc phân loại phụ thuộc rất nhiều vào phân đoạn từ đã nêu ở trên. Để giải quyết khó khăn này thì mô hình ngôn ngữ thống kê n-gram là lựa chọn tốt. Cách tiếp cận này có ưu điểm của mô hình ngôn ngữ dựa trên từ, đó là không phải giải quyết vấn đề phân đoạn từ rất khó đối với tiếng Việt đã nêu ở trên.
Hai là vấn đề lựa chọn đặc trưng, có thể nói lựa chọn đặc trưng trong phân loại văn bản là bước có nhiều vấn đề cần xử lý và khá khó khăn do đặc điểm của tiếng Việt, như việc lựa chọn số đặc trưng phù hợp, giải quyết số chiều của đặc trưng trong phân loại văn bản. Tuy nhiên khi sử dụng mô hình ngôn ngữ thống kê n-gram thì vấn đề này cũng được giải quyết.
Ngoài ra, mô hình ngôn ngữ dựa trên từ có kích thước nhỏ hơn mô hình dựa trên từ và cũng giảm bớt vấn đề dữ liệu thưa thớt. Tuy nhiên, sử dụng ngôn ngữ thống kê cũng có những nhược điểm như một số thuật ngữ sẽ không được nhận dạng tốt, hoặc nhận dạng sẽ sai. Hiệu ứng của ứng dụng n-gram trong phân loại văn bản là xác định tần suất xuất hiện trong nhóm đầu tiên của danh sách được sắp xếp. Trong thực tế, số lượng k-gram sẽ tăng lên đáng kể vì với mỗi k-gram xuất hiện, sẽ có 2(k+1)-gram xuất hiện cùng với nó.
- Sử dụng mô hình n-gram như một công cụ phân loại văn bản
Mô hình hóa ngôn ngữ thống kê liên quan đến việc xác định xác suất các chuỗi từ xuất hiện tự nhiên trong một ngôn ngữ. Đây là một nhiệm vụ phổ biến trong xử lý ngôn ngữ tự nhiên. Mô hình n-gram là một cách đơn giản và hiệu quả để thực hiện mô hình hóa ngôn ngữ và trong mô hình này, một từ được cho là chỉ phụ thuộc vào n-1 từ trước đó. Mặc dù nghiên cứu mô hình hóa ngôn ngữ cơ bản rất khó khăn, nhưng mô hình hóa ngôn ngữ đang ngày càng được chú ý vì nó đã được áp dụng thành công vào nhiều vấn đề thực tế.
Sử dụng phương phương pháp mô hình hóa ngôn ngữ thống kê n-gram để phân loại văn bản đó là áp dụng mô hình ngôn ngữ dựa trên âm tiết, tức là coi văn bản như một chuỗi các âm tiết liên tiếp. Lý do sử dụng này là để tận dụng mô hình ngôn ngữ dựa trên âm tiết để tránh vấn đề phân đoạn từ rất khó đối với tiếng Việt và do đó tránh được việc lựa chọn đặc trưng như đã chỉ ra trong phần 1). Mô hình ngôn ngữ dựa trên âm tiết nhỏ hơn mô hình ngôn ngữ dựa trên từ về mặt kích thước và nó cũng làm giảm vấn đề thưa thớt dữ liệu. Mục đích của mô hình hóa ngôn ngữ là dự đoán xác suất của các chuỗi từ tự nhiên; hay nói cách đơn giản hơn, là đặt xác suất cao cho các chuỗi từ thực sự xuất hiện (và xác suất thấp khác cho các chuỗi từ không bao giờ xuất hiện.
Một chuỗi từ w1w2...wT được đưa ra để sử dụng làm ngữ liệu thử nghiệm, chất lượng mô hình ngôn ngữ có thể được đo lường bằng giá trị thực nghiệm (hoặc entropy).
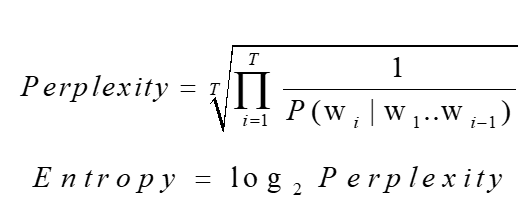
Chúng được sử dụng để đo lường khả năng của mô hình trong việc dự đoán một chuỗi các từ. Nếu perplexity thấp, điều đó có nghĩa là mô hình dự đoán các từ trong chuỗi tốt hơn. Ngược lại, perplexity cao cho thấy mô hình khó khăn trong việc dự đoán chuỗi từ đó. Mục tiêu của mô hình hóa ngôn ngữ là để có được perplexity nhỏ.
Trong thực tế, quá trình xây dựng mô hình ngôn ngữ n-gram có thể gặp phải phân phối không đồng đều, nghĩa là khi sử dụng mô hình n-gram theo công thức "xác suất thô", phân phối không đồng đều của ngữ liệu đào tạo có thể dẫn đến ước tính không chính xác. Khi phân phối n-gram thưa thớt, các cụm n-gram không xuất hiện hoặc chỉ xuất hiện một số ít lần, thì ước tính các câu chứa cụm n-gram sẽ có kết quả thấp hơn. Giả sử S là kích thước của vốn từ vựng, chúng ta sẽ có Sn cụm n-gram được tạo từ vốn từ vựng. Tuy nhiên, trên thực tế, số lượng cụm n-gram có ý nghĩa và thường xuyên xuất hiện là nhỏ. Khi tính toán xác suất của một câu, trong nhiều trường hợp, chúng ta sẽ có các cụm n-gram chưa từng xuất hiện trong dữ liệu huấn luyện. Điều này làm cho xác suất của câu bằng 0, trong khi câu có thể hoàn toàn đúng về mặt ngữ pháp và ngữ nghĩa. Để khắc phục tình trạng này chúng ta thường sử dụng một số phương pháp làm mịn để xử lý. Có các kỹ thuật làm mịn như sau:
- Làm mịn tuyệt đối
- Làm mịn tuyến tính
- Làm mịn Good-Turing
- Làm mịn Witten-Bell
Cho đến nay, có rất nhiều kỹ thuật tiên tiến để xử lý bài toán ngôn ngữ tự nhiên, nhưng mô hình ngôn ngữ thống kê n-gram vẫn là kỹ thuật được áp dụng rộng rãi và mang lại hiệu quả cao cho bài toán này vì những ưu việt và lơi thế của nó.
TÀI LIỆU THAM KHẢO
1. Wisam Abdulazeez Qader, Musa M.Ameen, Bilal I. Ahmed. An Overview of Bag of Words;Importance, Implementation, Applications, and Challenges. Conference: 2019 International Engineering Conference (IEC). June 2019.
2. Fuchun Peng and Dale Schuurmans, Combining Naive Bayes and n-Gram Language Models for Text Classification, ECIR 2003, LNCS 2633, pp. 335–350, 2003.
3. Maria Fernanda Caropreso, Stan Matwin, Fabrizio Sebastiani (2001). A Learner-Independent Evaluation of the Usefulness of Statistical Phrases for Automated Text Categorization, Text Databases and Document Management: Theory and Practice, Idea Group Publishing, Hershey, US, pp. 78--102
4. Fuchen Peng, Dale Schuurmans, Shaojun Wang. (2004). Augmenting Naïve Bayes Classifiers with Statistical Language Models, Information Retrieval, 7, 317-345.
5. Fuchun Peng, Xiangji Huang. Machine learning for Asian language text classification. May 2007 Journal of Documentation 63(3).
Tin mới
- Một số công cụ AI hỗ trợ giáo dục phổ biến hiện nay - 16/03/2025 15:20
- Khoa Kỹ thuật – Công nghệ tỏa sáng tại Giải đấu Pickleball chào mừng ngày Quốc tế Phụ nữ 8/3 - 09/03/2025 13:45
- Nâng cao năng lực đơn vị tư vấn giám sát thi công xây dựng công trình - 25/02/2025 08:35
- Một số công cụ dạy học hiện đại giúp đổi mới, tăng cường hiệu quả hoạt động kiểm tra, đánh giá sinh viên - 19/02/2025 15:00
- Sinh viên K14 ngành Công nghệ thông tin tham gia thực tập tốt nghiệp năm 2025 - 18/02/2025 03:13
Các tin khác
- Giao lưu học thuật giữa sinh viên Khoa Kỹ thuật - Công nghệ, Trường Đại học Hà Tĩnh với sinh viên Trường Đại học Induk, Hàn Quốc - 10/01/2025 15:54
- TCVN 5575:2024 Tiêu chuẩn Quốc gia về thiết kế kết cấu thép có gì mới - 28/12/2024 08:44
- Phương pháp thi công nhà thép tiền chế đúng kỹ thuật - 19/12/2024 23:29
- Giảng viên Khoa Kỹ thuật – Công nghệ tham dự hội thảo “Trí tuệ nhân tạo và tương lai giáo dục đại học – AI4Edu 2024” - 17/12/2024 00:30
- Tìm hiệu phương pháp chuyển đổi hình ảnh kỹ thuật số rgb thành hình ảnh xám và cài đặt thực nghiệm - 22/11/2024 08:33