





Bài toán dự báo là bài toán có thể sử dụng các mô hình học máy để dự đoán giá trị của một biến số trong tương lai dựa trên các giá trị của biến số đó trong quá khứ. Các bài toán dự báo thường gặp trong thực tế bao gồm: Dự báo thời tiết; Dự báo doanh số bán hàng; Dự báo tình trạng bệnh tật; Dự báo kết quả thi… Bài viết này trình bày ứng dụng thuật toán SVM cho dự báo điểm thi của sinh viên thông qua các đặc trưng: Thời gian giờ ngủ, Thời gian tự học, Thời gian giải trí của sinh viên
Thuật toán SVM
2.1 Thuật Toán
Thuật toán Support Vector Machine (SVM) là một thuật toán máy học được sử dụng chủ yếu cho các vấn đề phân loại và hồi quy. Ý tưởng cơ bản của SVM là tìm ra đường phẳng (hoặc siêu phẳng) tốt nhất để phân chia không gian đặc trưng thành các lớp. Trong trường hợp phân loại nhị phân, mục tiêu là tìm một ranh giới quyết định sao cho khoảng cách giữa các điểm dữ liệu và đường phẳng là lớn nhất.
Thuật toán SVM cũng có thể được mở rộng để xử lý các tình huống phân loại đa lớp và thậm chí là dự báo hồi quy. Kernel trick là một khía cạnh quan trọng của SVM, cho phép ánh xạ dữ liệu từ không gian đặc trưng ban đầu sang một không gian cao chiều, giúp SVM giải quyết các vấn đề phức tạp hơn.
2.2. Ưu điểm, nhược điểm của thuật toán SVM
Ưu điểm:
- Có thể xử lý phi tuyến tính bằng kỹ thuật Kernel.
- Tạo độ bền tốt (Robustness)
- Có thể được kiểm soát bằng kỹ thuật Soft Margins.
Nhược điểm: Không phù hợp với tập dữ liệu lớn vì mất nhiều thời gian để huấn luyện.
3. Cài đặt thực nghiệm
3.1. Dữ liệu: Dữ liệu gồm các đặc trưng Giờ học, giờ ngủ, giờ chơi gâm, kết quả thi (kết quả thi 0 là trượt, 1 là đậu). Bộ dữ liệu gồm 142 bản ghi, mỗi bản ghi mô tác các đặc trưng thực tế của một sinh qua khảo sát, làm dữ liệu huấn luyện cho bài toán.
(142 bộ dữ liệu trong file)
3.2. Thực nghiệm (step by step Coding)
- import pandas as pd
- import numpy as np
- importpyplot as plt
- frommplot3d import Axes3D
- frommodel_selection import train_test_split
- fromsvm import SVC
- frommetrics import accuracy_score
- frommetrics import accuracy_score, classification_report
- # Load data
- data =read_csv("./csv/student_data_.csv")
- …….
- # Create DataFrame from input data
- input_data_df =DataFrame(
- {
- "Study Hours": [study_hours],
- "Sleep Hours": [sleep_hours],
- "Play Game Hours": [gaming_hours],
- }
- )
- # Predict the exam result
- prediction =predict(input_data_df)
- # Print the results
- result = "Pass" if prediction[0] == 1 else "Fail"
- print(f"name: {student_name}, exam: {result}")
- # Plot the results on a 3D scatter plot
- color = "green" if prediction[0] == 1 else "red"
- scatter(study_hours, sleep_hours, gaming_hours, c=color)
- # Display the hyperplane with a lower alpha value for a thinner appearance
- xx, yy =meshgrid(X.iloc[:, 0], X.iloc[:, 1])
- zz = (
- -intercept_[0] - model.coef_[0, 0] * xx - model.coef_[0, 1] * yy
- ) /coef_[0, 2]
- plot_surface(xx, yy, zz, alpha=0.1, color="blue", label="Hyperplane")
- # Set axis labels
- set_xlabel("Study Hours")
- set_ylabel("Sleep Hours")
- set_zlabel("Play Game Hours")
- set_title("SVM classifier")
- # Display the 3D plot
- show()
4. Kết quả thực nghiệm và bình luận
4.1. Kết quả thực nghiệm :
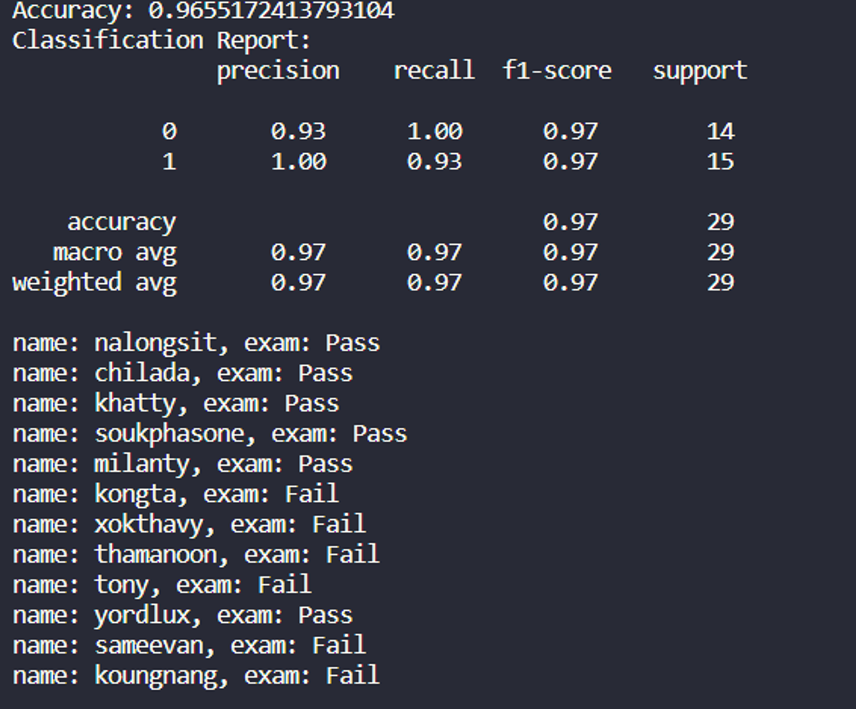
4.1.1 giải thích classification report
1. Accuracy (Độ chính xác): 0.9655172413793104
- Độ chính xác là tỷ lệ giữa số lượng dự đoán đúng và tổng số mẫu trong tập kiểm tra.
- Trong trường hợp này, độ chính xác là khoảng 96.55%.
2. Classification Report (Báo Cáo Phân Loại):
- Precision (Chính xác):
- Precision là tỷ lệ giữa số lượng dự đoán đúng của một lớp và tổng số lượng dự đoán thuộc lớp đó.
- Ví dụ, precision của lớp 0 là 0.93, nghĩa là 93% trong số các mẫu được dự đoán là lớp 0 thực sự là lớp 0.
- Recall (Độ phủ): Recall là tỷ lệ giữa số lượng dự đoán đúng của một lớp và tổng số lượng mẫu thực sự thuộc lớp đó. Ví dụ, recall của lớp 1 là 0.93, nghĩa là mô hình bắt kịp được 93% trong số mẫu thực sự thuộc lớp 1.
- F1-Score: F1-score là trung bình điều hòa giữa precision và recall. Nó được sử dụng khi chúng ta muốn cân nhắc cả precision và recall. Đối với cả lớp 0 và lớp 1, F1-score đều là khoảng 0.97, đây là một kết quả tốt.
- Support: Support là số lượng mẫu thực sự thuộc mỗi lớp trong tập kiểm tra.
- Macro Avg: Là trung bình của các giá trị precision, recall và f1-score trên tất cả các lớp. Macro Avg không quan tâm đến kích thước của các lớp, nó tính toán trung bình một cách bình đẳng cho mỗi lớp.
- Weighted Avg: Là trung bình có trọng số theo số lượng mẫu thực sự thuộc mỗi lớp. Weighted Avg đánh giá hiệu suất của mô hình với trọng số lớn hơn đối với các lớp có số lượng mẫu lớn hơn.
4.2. Đồ thị kết quả và siêu phẳng phân lớp
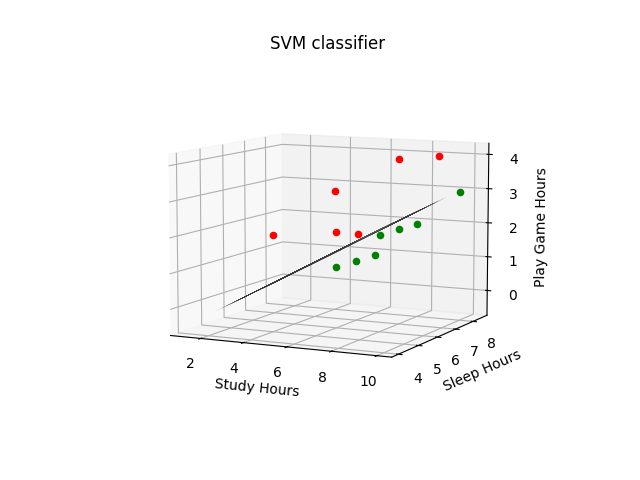
5. Kết luận
Support Vector Machine (SVM) là một thuật toán học máy phân lớp được sử dụng rộng rãi trong nhiều ứng dụng thực tế. SVM hoạt động bằng cách tìm một siêu phẳng trong không gian dữ liệu sao cho hai lớp dữ liệu được phân tách nhau một cách tối ưu, đồng thời đảm bảo khoảng cách giữa siêu phẳng và các điểm dữ liệu của hai lớp là lớn nhất có thể. Thực nghiệm bài toán dự báo điểm thi của sinh với thuật toán SVM với tập dữ liệu đầu vào trong bài viết cho kết quả chính xác lên đến 97% trong quá trình kiểm thử. Tuy nhiên trên thực tế, kết quả này còn phụ thuộc các đặc trưng của dữ liệu khảo sát trong khuôn khổ kết quả thi nghiêm túc được khảo sát.
6. Tài liệu tham khảo
https://www.nerd-data.com/svm/
https://viblo.asia/p/gioi-thieu-ve-support-vector-machine-svm-6J3ZgPVElmB
Tin mới
- Đăng ký tài khoản chát GPT-4o miễn phí - 20/08/2024 08:14
- Dự đoán nhu cầu sử dụng mạng di động và đặc điểm mạng 6G - 20/08/2024 07:59
- Một số hướng dẫn thí sinh đăng ký xét tuyển đại học năm 2024 - 20/07/2024 07:36
- Thông báo tuyển sinh Liên thông ngành KTXD - 20/07/2024 07:27
- Thông báo Tuyển sinh chương trình hợp tác đào tạo thí điểm năm 2024 giữa Trường Đại học Hà Tĩnh và Đại học Quốc gia Hà Nội - 18/07/2024 02:03
Các tin khác
- Khoa Kỹ thuật – Công nghệ tổ chức thành công Lễ bảo vệ khóa luận tốt nghiệp năm học 2023-2024 - 13/06/2024 08:29
- Kế hoạch học GDQP AN năm học 2023-2024 - 25/05/2024 09:06
- Lê Hoàng Anh với ước mơ trở thành chuyên gia CNTT - 20/05/2024 14:05
- Những mái nhà cỏ - nét độc đáo từ đan mạch - 20/05/2024 13:59
- Khoa Kỹ thuật – công nghệ tổ chức Hội nghị sinh viên nghiên cứu khoa học lần thứ XVII - 12/04/2024 13:05