





K-Means là một thuật toán phân cụm dữ liệu kinh điển trong học máy (Machine learning), thuộc lớp thuật toán học không giám sát (Unsupervised learning). Bài viết sau đây nhằm giúp các bạn sinh viên CNTT hiểu rõ hơn về thuật toán trong phân cụm dữ liệu và ứng dụng thuật toán này trong phần nén ảnh của môn học Xử lý ảnh dành cho sinh viên năm 4 chuyên ngành CNTT.
1. Giới thiệu về thuật toán K-Means
Thuật toán K-Means chuẩn được đề xuất lần đầu tiên bởi Stuart Lloyd của Bell Labs vào năm 1957 nhưng không được xuất bản dưới dạng một bài báo cho đến tận năm 1982, năm 1965, Edward W.Forgy đã công bố phương pháp tương tự, do đó phương pháp này thường được gọi là Lloyd-Forgy.
Thuật toán K-Means
Bước 1. Tạo các tâm cụm ngẫu nhiên
(1)
Bước 2. Gán các điểm dữ liệu xi (iÎ[1, N]) vào các tâm cụm mk (kÎ[1, K])
- Với mỗi điểm dữ liệu, ta tính khoảng cách Euclid của nó đến các tâm cụm được định nghĩa bởi hàm (xi-mk) (2), tập hợp các điểm được gán vào cùng một tâm cụm sẽ tạo thành một cụm.
- Đặt là các vector cho mỗi cặp xi, yik = 1 nếu xi thuộc cụm k và yij=0 với j≠k.
- Khi đó ta có biểu thức sau:
(3)
- Tổng bình phương khoảng cách từ một điểm thuộc cụm dữ liệu xi thuộc nhóm mk được xác định theo công thức:
(4)
- Khi đó hàm mất mát (lost function) được định nghĩa:
(5)
Với M là tập hợp các cụm tại (1)
Y, M = argminY,M (6)
Bước 3. Cập nhật lại vị trí tâm cụm và gán lại các điểm dữ liệu vào từng cụm sau khi đã xác định được khoảng cách nhỏ nhất từ các công thức (4), (5), (6).
- Lặp lại cho đến khi vị trí tâm các cụm không thay đổi, tổng khoảng cách từ các điểm dữ liệu đến các tâm cụm khi đó sẽ đạt nhỏ nhất, gọi là lỗi (Error) nhỏ nhất.
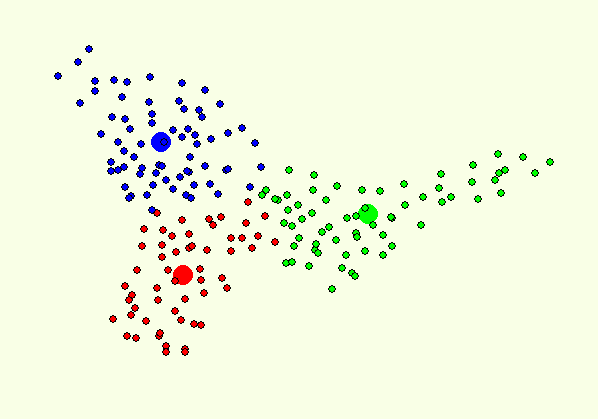
Hình 1. Sử dụng K-Means để phân cụm dữ liệu, số điểm dữ liệu N=150; K=3
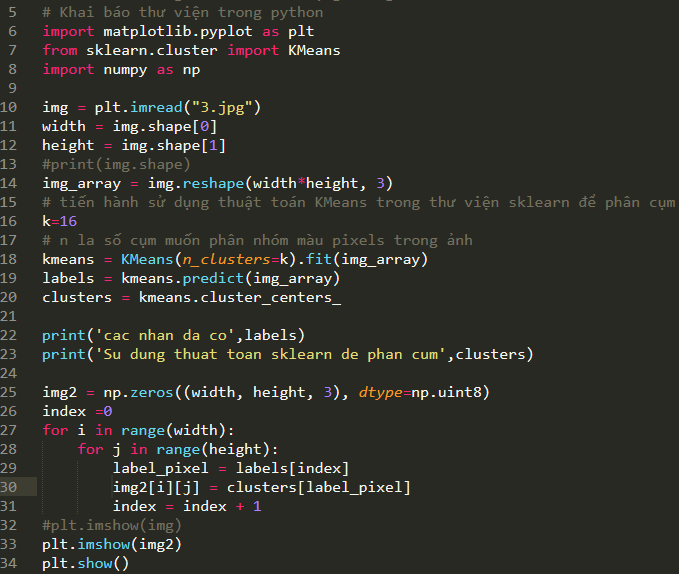
2. Sử dụng ngôn ngữ lập trình Python cài đặt thuật toán K-Means trong nén ảnh màu
Từ thuật toán K-Means trên, mỗi bức ảnh màu chúng ta tiến hành phân cụm theo các thông số màu R-G-B từ các pixels của ảnh. Khi xác định được những màu chủ đạo (màu chiếm đa số pixels trong ảnh), chúng tôi tiến hành phân cụm và thay thế mỗi giá trị pixel đó bởi giá trị trung bình các pixels trong ảnh, chúng tôi sử dụng ngôn ngữ lập trình python thử nghiệm thuật toán K-Means để thực hiện nén ảnh. Chương trình chúng tôi sử dụng một số thư viện như matplotlib, sklearn và numpy trong quá trình cài đặt.
3. Kết luận
Qua kết quả chạy thực nghiệm khi sử dụng thuật toán phân cụm K-Means với số cụm K=16 để nén ảnh, ảnh đã giảm dung lượng từ 4.3MB xuống còn 209KB (b), với K=4 dung lượng giảm xuống còn 159KB (c). Mặc dù chất lượng ảnh đã không được như ảnh gốc vì ảnh sau khi nén là ảnh 16 màu hoặc 4 màu tương ứng với K=16 và K=4 cụm được K-Means tiến hành phân cụm và thay thế giá trị trung bình các chỉ số R-G-B trong từng pixel của ảnh gốc. Tuy nhiên ảnh sau khi nén vẫn giữ được đầy đủ đặc tính để thực hiện phân tích và xử lý ảnh, do đó K-Means được ứng dụng cài đặt thực nghiệm, mô phỏng trong lĩnh vực phân tích và xử lý ảnh cũng như mô phỏng thực nghiệm phân cụm dữ liệu trong lĩnh vực học máy.
Tài liệu tham khảo:
[1]. Shokri Selim, K-Means-Type Algorithms: A Generalized Convergence Theorem and Characterization of Local Optimality, IEEE transactions on pattern analysis and machine intelligence, vol. pami-6, no. 1, january, 1984.
[2]. Vu Huu Tiep, blog https://machinelearningcoban.com.
Tin mới
- Một số Biện pháp bảo đảm An toàn lao động trên công trường xây dựng - 28/12/2021 02:36
- Xu hướng của Ngành công nghệ thông tin? - 21/12/2021 02:02
- Một số ứng dụng hỗ trợ dạy học trực tuyến - 19/12/2021 16:32
- Một số chính sách mới tác động đến thị trường bất động sản - 22/11/2021 01:28
- Khoa Kỹ thuật - Công nghệ tổ chức giao lưu trực tuyến giữa cựu sinh viên với giảng viên và sinh viên của Khoa - 21/11/2021 08:59
Các tin khác
- Thuật toán K-Means và ứng dụng trong nén ảnh với ngôn ngữ lập trình Python - 16/11/2021 02:46
- Bài giảng E – learning là gì? - 24/10/2021 13:57
- Hội nghị cán bộ viên chức khoa Kỹ thuật công nghệ Năm học 2021 - 2022 - 24/10/2021 08:45
- Hội nghị cán bộ viên chức khoa Kỹ thuật công nghệ Năm học 2021 - 2022 - 24/10/2021 08:42
- Những phần mềm chống vi-rút được đánh giá tốt nhất cho năm 2021 - 01/10/2021 01:50